How to host your website on S3
s3 amazon hosting serverless python, scripting, webhostingS3 Hosting: What and Why #
S3 started as a file hosting service on AWS that let customers host files for cheap on the cloud and provide easy access to them. Along the way amazon introduced more features to the service, and one that I am particularly excisted about is web hosting. This means that now we have the ability to host websites on an S3 bucket and serve them over http as a website.
S3 is not as feature rich as other Web hosting services like Apache and IIS but it still has it's uses. If your aim is to host a static website that does not do a lot of dymaic operations[^1], hosting your webpages on s3 is not a bad idea. Hosting is significantly cheaper[^4] as you only pay for storage and data transfer, and you can leverage S3's redundancy and geo replication, to have your pages load fast anywhere in the world.
If Hosting your webpage on S3 sounds like a good idea read on, the next section will show you how to manually upload and set up an S3 bucket for website hosting. If your page is static a one time setup will be sufficient, but further down I also explain one way of automating the deployment to S3 in order to push changes frequently. It can be done manually everytime but we are not barbarians.. so I wrote a script to do all the heavy lifting. If you are not interested in the inner workings of the script you can find the finished script here{:target="_blank"}.
S3 Hosting: For Barbarians (Manual Setup) #
Let's say we have a small website that contains html, some css and some javascript and we want to host it on S3. I'm using the clean bootstrap theme for this example{:target="_blank"}
-
Login to your AWS console, and open the S3 section
-
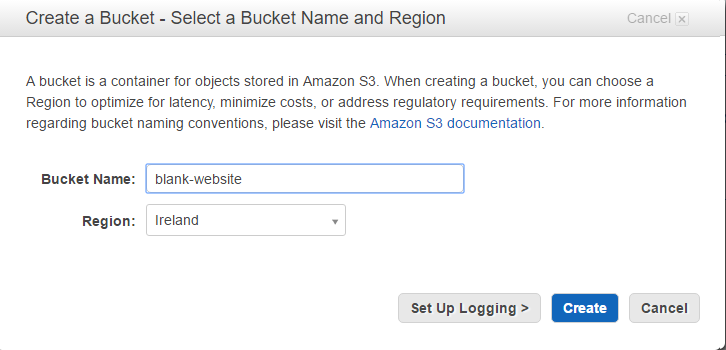
Create a bucket
- Click create bucket button: Create S3 bucket
- Select the region where you want to host your site
- Type a name for your bucket
- Bonus tip: if you want to point a domain to your website I found that domain forwarding only works if you call the bucket same as your domain. E.g if you website domain is ducksducksducks.com name your bucket www.ducksducksducks.com
- (Optional) Setup logging if it you and hit click create
-
Next Upload your files to the bucket you just created. If you are using the same example files, upload the contents of dist into the bucket so that index.html sits int he root of the bucket[^2].
-
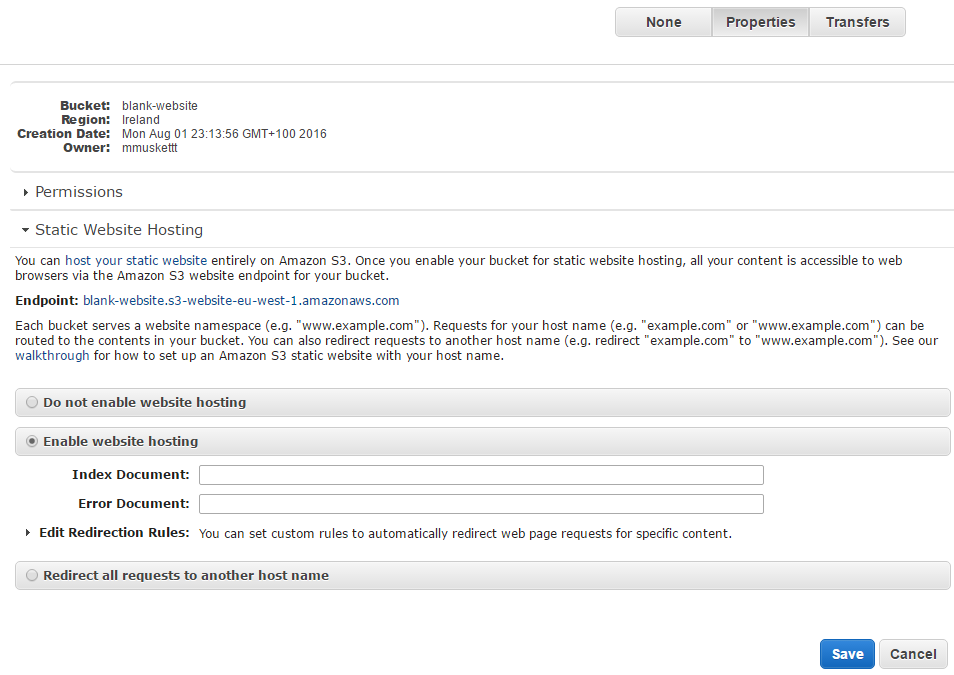
Next we'll enable file hosting.
- Highlight the bucket
- Click on properties (top right)
- Expand Static web hosting tab
- Choose enable website hosting
- Specify the index Document in this scenario its index.html
- Hit save button and you are done!
-
In the website hosting settings you can find the bucket's url, navigate to that link and your site should open in a new tab. Voila!
-
If you have your own domain, point your www dns cname to this url and once the dns refreshes, navigating to the domain url will open the index document of your bucket
{kind=link}
{kind=link}
Note: If you reupload any of the files they may loose their public permissions. To fix this, Click on the file in the S3 interface and change the file permission so that everyone can open/download
As previously mentioned if your project is a one time set up doing it manually is easy, but if you plan on updating your project often you might be interested in automating this process.
S3 Hosting: The non-barbarian way (Scripting) #
Using python, we can write a script that uploads our folder contents to a bucket of our choice, and set the correct permissions to all the files. If you are not interested in the inner workings of the script you can look at the finished script here. But if you are first we'll need to get all the files we intend to upload
from __future__ import print_function
import os
def getFiles(baseFolder):
file_paths = []
for root, directories, files in os.walk(baseFolder):
for filename in files:
filepath = os.path.join(root, filename)
file_paths.append(filepath)
return file_paths
filesToProcess = getFiles('dist')
print ('Found ' + len(filesToProcess).__str__() + ' files to process')The above function uses os.walk to loop through all the files and sub directories in the dist folder, and keeps their relative paths in the file_paths array for other functions to consume.
Next we want to upload the files to our bucket. For that we need the boto3 module so let's import that in addition to some error handling and also a function that will upload file files for us.
To work with Boto3 you will need to add a key and a secret. You can pass them as parameters but I prefare to specify a .aws file and set the credentials there[^5]. I'm using a profile called deploy as I have keys with different sets of permissions for other projects.
import boto3
from botocore.exceptions import ClientError
def upload_to_s3(bucketName, sourceDir):
print("Starting script")
session = boto3.Session(profile_name='deploy')
client = session.client('s3')
uploadFileNames = getFiles(sourceDir)
print("Found " + len(uploadFileNames).__str__() + ' files')
for filename in uploadFileNames:
try:
destName = os.path.join(*(filename.split('\\')[1:])).replace('\\','/')
#running this on windows (shocking I know!) so I added .replace('\\','/')
#or else s3 wont recognize the path as separate folders
print ("Uploading file " + filename + ' to ' + destName)
client.upload_file(filename, bucketName, destName)
except ClientError as err:
print("Failed to upload artefact to S3.\n" + str(err))
return False
except IOError as err:
print("Failed to access artefact in this directory.\n" + str(err))
return False
return TrueOne more line to call the upload function
upload_to_s3('blank-website','dist\\')and we are done! Well.. not so fast. If you try to run this you will notice that the files upload, but the website stops working. That's because the uploaded files don't have the right meta data information. I could not find a way to set that using the simple upload_file function, so I had to resort to Object.put. In the following function I also decided to move the loop that iterates over the filepaths outside the function for easier composition and testing.
import boto3
from botocore.exceptions import ClientError
from mimetypes import MimeTypes
def upload_file(bucket_name,filePath):
session = boto3.Session(profile_name='deploy')
client = session.client('s3')
s3 = session.resource('s3')
destname = os.path.join(*(filePath.split('\\')[1:])).replace('\\','/')
print ("Uploading file " + filePath + ' to ' + destname)
try:
data = open(filePath, 'rb')
ftype, encoding = MimeTypes().guess_type(filePath)
conType = ftype if ftype is not None else encoding if encoding is not None else 'text/plain'
s3.Object(bucket_name, destname).put(Body=data,ContentType=conType,ACL='public-read')
except ClientError as err:
print("Failed to upload artefact to S3.\n" + str(err))
return False
except IOError as err:
print("Failed to access artefact in this directory.\n" + str(err))
return False
return TrueHere I added another library mimetypes that as the name suggests, determines the mime type of a file depending on file extension. Now when calling Object.put we pass the bytes to upload, its mimetype and set its ACL so that everyone can view the file
Running the updated code yields much better results.
[upload_file('blank-website',x) for x in getFiles('dist\\')]Give it a go. If you want something basic to get you going this should be enough, but there is some more optimization that can be done. Most modern web servers and browsers host and ask for compressed files in order to reduce the amount of data transferred. This speeds up your website significantly if there is a lot of css and js to download.
Speed up your site using compression #
So now you want your website to load faster? S3 is a very basic hosting service and does not do this automatically for us but there is a hacky way of achieving that. All the text files that make up your website (mainly all html, js and css) in your folder can be manually compressed using gzip. These files won't be opened unless unzipped, but if we add a content-encoding metatag for each of these files, a browser will be made aware that the file in question is compressed and will uncompress it before reading it. Easy! but our script needs some changes.
First up a few functions:
import gzip
from shutil import copyfile
dontZip = ['.jpg','.png','.ttf','.woff','.woff2','.gif']
def zipFile(input, output):
print ('Zipping ' + input)
dirname = os.path.dirname(output)
if not os.path.exists(dirname):
os.makedirs(dirname)
with open(input) as f_in, gzip.open(output, 'wb') as f_out:
f_out.writelines(f_in)
def copyFile(input, output):
print ('Copying ' + input)
dirname = os.path.dirname(output)
if not os.path.exists(dirname):
os.makedirs(dirname)
copyfile(input, output)
def isZipFile(fileName):
extension = os.path.splitext(fileName)[1]
if extension in dontZip:
return False
return TrueFirstly we need a staging folder, called out, where we'll place all the zipped files. But Images and fonts are already compressed so compressing them again won't do any good, thus we need a copyFile function in order to also copy the files that don't need compression into the staging folder. In edition there is a isZipFile function that will decide if a file should be zipped or copied.
We can all of the above using
[zipFile(x,'out\\' + x) if isZipFile(x) else copyFile(x,'out\\' + x) for x in getFiles('dist')]Running this code will create an out folder and if you open any of the text files in it you will notice that they are full of funny unicode characters.. that is good. In upload_file we also need to modify the put function to also specify an encoding
def upload_file(bucket_name,filePath):
...
destname = os.path.join(*(filePath.split('\\')[2:])).replace('\\','/') # root level has changed
...
ftype, encoding = MimeTypes().guess_type(filePath)
conType = ftype if ftype is not None else encoding if encoding is not None else 'text/plain'
encType = 'gzip' if isZipFile(filePath) else ''
s3.Object(bucket_name, destname).put(Body=data,ContentEncoding=encType,ContentType=conType,ACL='public-read')
...and run all the above again
[zipFile(x,'out\\' + x) if isZipFile(x) else copyFile(x,'out\\' + x) for x in getFiles('dist')]
[upload_file('blank-website',x) for x in getFiles('out\\dist\\')]
And now we have a compressed website hosted on S3!
Further optimization #
When Uploading a project with a lot of files I found the script to be a bit slow so I added some threading to speed things up
import threading
from multiprocessing.pool import ThreadPool
pool = ThreadPool(processes=40)
pool.map(lambda x : upload_file('upload-gzip-test-2',x), getFiles('out\\dist\\'))
Group up all the script parameters to the top and even pass them as arguments, and you have a solid script that allows you to one click publish your projects straight to S3!
P.S Don't forget to minify your JS and CSS
You get bonus points if you include the script into an automation tool that automatically publishes when ever you push your changes to source control, but that's a story for another time.
I Hope you find this article useful. You can find the completed script on my github[^3].
Footnotes #
[^1]: Dynamic operations and remote calls are still possible, so you can have a page that calls a rest api, but that's beyond the scope of the document. [^2]: I use cyberduck to upload files as I find it less clunky than the S3 console, but thats entirely up to you. [^3]: Github [^4]: S3 pricing [^5]: A New and Standardized Way to Manage Credentials in the AWS SDK